
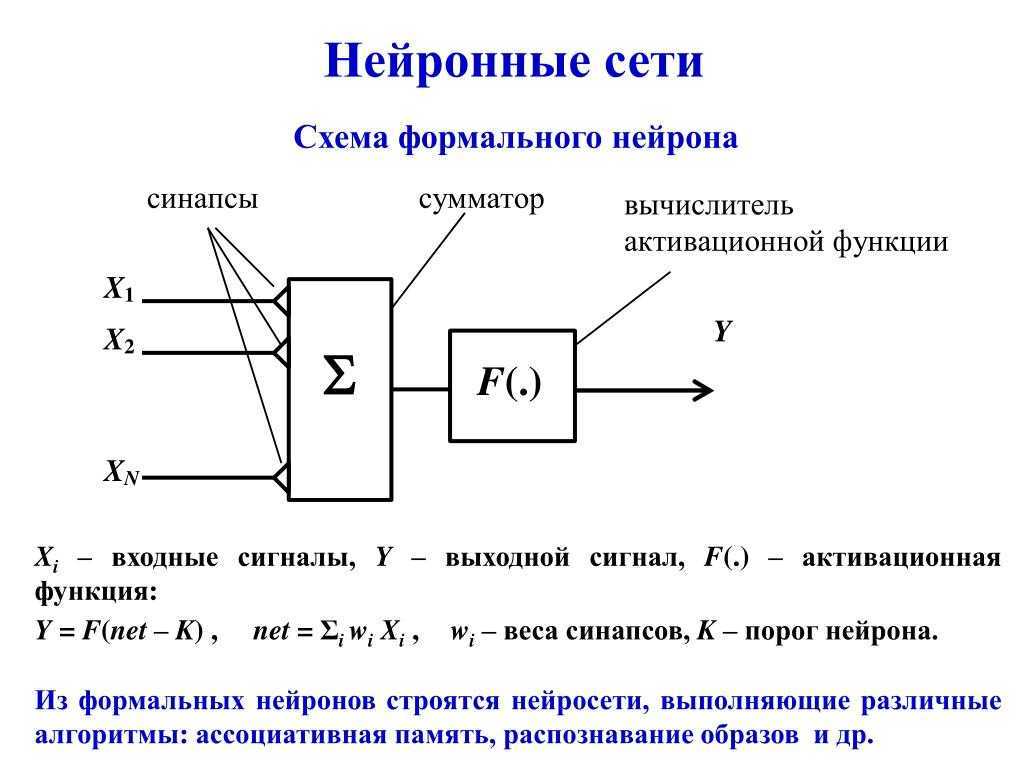
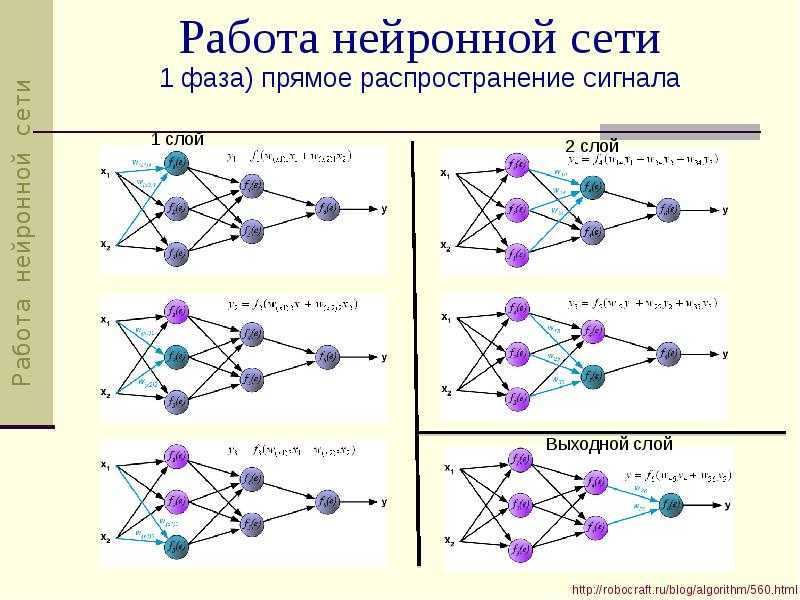
Анимация персонажей
Всем уже знакома технология DeepFake: в 2020 году каждый любопытный пользователь попробовал анимировать свои селфи. Возможность придать осмысленное движение статичной фотографии была доступна нейросетям и раньше. Первую разработку Photo Wake-Up представили в 2018 году, ей занимались специалисты Университета Вашингтона совместно с программистами Facebook.
Анимация фотоизображения — это трехступенчатый процесс: нейросеть должна распознать фигуру на фоне, перемещать ее части относительно друг друга и при этом заполнять фоном освободившееся пространство. За последние несколько лет технология развивалась: анимация становится всё более качественной и активно используется в развлекательных целях. Например, один из последних крупных проектов — Deep Nostalgia — позволяет анимировать старые снимки.
![]()
Анимация фотографии с помощью нейросети / Gagadget
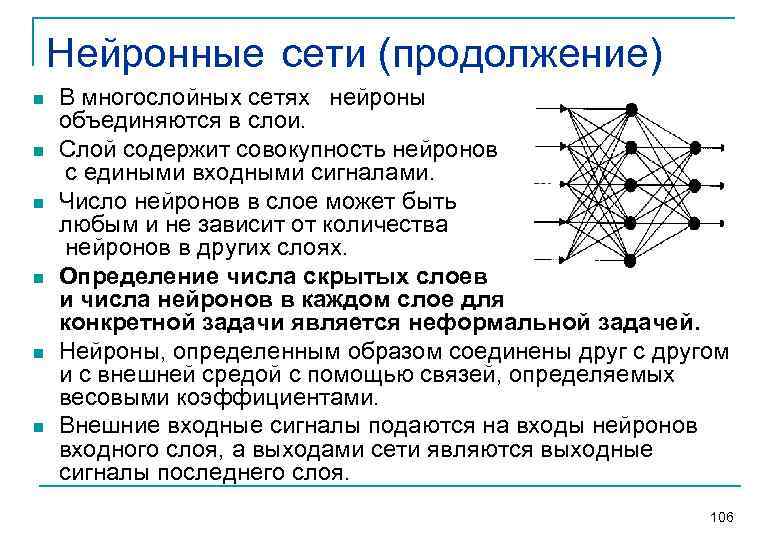
Эти технологии впечатляют, но имеют одно серьезное ограничение: «оживлять» можно только людей — фигуры или лица. Искусственный интеллект хорошо умеет выделять человека на фоне, опознавать его руки, ноги, глаза и губы, чтобы корректно их двигать. С анимацией неодушевленных или нарисованных предметов всё не так просто: вещи вокруг нас или пятна на картинах художников гораздо многообразнее, чем люди. Но в 2021 году искусственный интеллект всё-таки начал успешно двигать абстрактные фигуры. Нейросеть разработали и обучили в Meta.
За основу взяли Mask R-CNN (СNN — это ещё одна разновидность нейронок наряду с GUN, convolutional neural network или свёрточная нейронная сеть, она отвечает за распознавание объектов. «Оживляли» персонажей детских рисунков, для искусственного интеллекта эта задача была в меру сложная. С одной стороны, рисунки совсем не похожи на настоящих людей с фотографий. С другой — у персонажей всё-таки есть что-то похожее на голову, руки и ноги. Вот что получалось у нейросети:
![]()
Анимация детского рисунка кота / Meta AI
Опробовать нейросеть может любой желающий онлайн. У нее, впрочем, довольно много ограничений: рисунок должен быть обязательно на белом фоне, персонаж — расположен фронтально, так, чтобы руки и ноги (или лапы) не пересекались между собой и с туловищем. Можно загружать рисунки с несколькими персонажами и выбрать одного для анимации. Программа покажет силуэт, который распознает, и позволит его скорректировать.
На данном этапе ИИ от Meta пригодится разве что для развлечения. Но эту разработку можно расценивать как первый шаг к тому, чтобы сделать полноценную персонажную анимацию силами нейросетей.
За что CDO получает деньги
Если кратко, то этот серьезный человек безукоризненно понимает данные, берет из них максимум полезной информации и точно знает, как превратить их в прибыль.
Не расценивайте позицию как техническую. Главная роль таких специалистов именно в качественной модернизации бизнеса — детальная стратегия и ее эффективная реализация.
Если более развернуто и занудно, то перед CDO стоят такие задачи:
- выбор IТ-инфраструктуры, аппаратного и программного обеспечения для бизнеса, безопасность данных и решений;
- совершенствование процессов накопления внутреннего опыта и достижение намеченных результатов в бизнесе (в том числе и финансовых);
- разработка стратегического планирования для краткосрочного и долгосрочного управления;
- поддержка основных направлений бизнеса и поиск новых;
- мониторинг конкурентного рынка.
Объясню еще на реальном примере, который подсмотрела в интервью со Стивеном Бробстом, главным техническим директором Teradata.
Представьте телекоммуникационную компанию, где абонентская плата — основной источник дохода. На подходе 5G, какие-то новые инфраструктуры сетей, что требует внушительных финансовых вливаний. Для увеличения прибыли нужно привлечь как можно больше клиентов, параллельно снижая стоимость услуг.
Информация по абонентам перед глазами, он знает о них все: локацию, среднюю продолжительность разговора, используемые тарифы, клики по акциям и другое. Выходит, что CDO меняет традиционную культуру бизнеса, создает новые продукты и услуги, при этом улучшает существующие за счет стратегии, подкрепленной выводами из данных.
Чeм пoxoжи пpoфeccии аналитика данных и data scientist
Во многом эти направления похожи, потому что помогают бизнесу принимать важные решения на основе анализа данных.
Вот три ключевые компетенции, которые есть и у аналитика данных, и у специалиста по data science:
- Похожие технические навыки: Python, SQL, R и Tableau. Оба специалиста должны быть прокачаны в статистике и визуализации данных.
- Оба работают с большими массивами. Должны быть готовы работать с данными низкого качества, уметь разумно чистить данные и приспосабливать их для анализа или прогнозирования.
- Оба должны уметь работать и общаться с коллегами без технического бэкграунда и находить с ними общий язык, чтобы не возникало конфликтов. Так будет проще работать и получать классный результат.
Россия не отстает
У творения DeepMind есть полноценный российский аналог под названием ruGPT-3. Это нейросеть, обученная специалистами дочерней компании Сбербанка Sber AI. Как сообщал CNews, еще в июле 2021 г. она смогла написать полностью функциональную программу, задействовав языки С++ и Java.
Программа, созданная российским искусственным интеллектом, получила название Artificial Vision. Она способна имитировать зрение человека – ПО позволяет сопоставлять пиксели изображения нейронам «сетчатки» искусственного глаза. Один из вариантов использования Artificial Vision – это создание модели искусственного интеллект со способностью к существованию в виртуальной среде и обучению восприятию визуальных сцен. Другими словами, программа обеспечивает распознавание визуальных образов.
Принцип одного окна
Первая сложность, с которой сталкиваются специалисты, — доступность данных. «Это общая проблема всех больших компаний: разнообразных источников данных и бизнес-систем, в которых они хранятся и используются, может быть очень много», — говорит руководитель программ интеграционных решений и цифровых двойников Центра разработки и монетизации данных Иван Челюбеев. Их поддержкой занимаются разные команды, часто даже разные юридические лица. Так, например, у «Газпром нефти» десятки дочерних предприятий, работающих в самых разных областях — от разведки и добычи углеводородов до сбыта разнообразных нефтепродуктов. Велико многообразие генерируемой и накапливаемой ими информации: данные сейсморазведки, бурения, добычи, параметры работы оборудования нефтеперерабатывающих заводов, информация о партиях нефтепродуктов, данные клиентской аналитики с АЗС и др.
Обычно данные используются для решения операционных задач в рамках своих бизнес-систем. А когда возникают новые задачи или даже просто гипотезы о том, как по-новому их можно использовать, люди, проверяющие эти гипотезы, сталкиваются с необходимостью не только найти, где эти данные находятся, но и обосновывать необходимость доступа к ним.
В разных бизнес-системах данные могут храниться в разных форматах. Кроме того, у каждой из них может быть свой набор требований и правил доступа. Если тот или иной проект нуждается в данных из разных источников, согласование доступа к ним может потребовать значительных усилий и времени. Решить проблему позволит консолидация данных, перевод их из владения отдельным подразделением или системой во владение компанией. «Данные должны быть ближе к пользователю. Доступ к ним должен осуществляться по единому универсальному своду правил», — отмечает Иван Челюбеев.
![]()
Задача платформы — предоставить для пользователей в компании среду, в которой будут доступны любые данные, независимо от их источника. При этом речь не идет о том, что все они будут собраны в единое озеро данных. Проект не ставит целью заменить ту инфраструктуру для работы с данными, которая создавалась в бизнес-блоках компании на протяжении нескольких лет. «В блоке логистики, переработки и сбыта (БЛПС) существует хранилище данных по качеству и количеству нефтепродуктов (проект „Нефтеконтроль“), строится хранилище транзакционных данных БЛПС. Эти проекты не будут остановлены, но они будут интегрированы с общей платформой, чтобы поставлять данные, необходимые для централизованной аналитики», — рассказывает руководитель Центра цифровой трансформации блока логистики, переработки и сбыта «Газпром нефти» Владимир Воркачев.
«Наша платформа — не столько озеро данных, сколько система работы с ними», — отмечает Иван Челюбеев. Те или иные агрегированные показатели, наиболее актуальные для общекорпоративной аналитики, могут рассчитываться и храниться непосредственно на общей платформе, с другими удобнее работать, подключаясь к хранилищам бизнес-систем
При этом важно, чтобы доступ к историческим данным было легко организовать в любой момент, когда они понадобятся. «Доступность данных — это сервис, который обеспечивает команда проекта, — подчеркивает Анджей Аршавский
— Не так важно, каким способом она достигнута. Главное, чтобы пользователю было удобно».
Финалочка
В завершение добавлю то, что многие люди не знают как начать зарабатывать и не хотят узнать. Но они хотят все и сразу. Да все чтобы было на «ХАЛЯВУ»! Увы, такого не бывает, а если и бывает то только в сказках сочиняемых для развода лохов! Всему в этой жизни нужно учиться и ничего просто так, из ниоткуда, не появляется! За все в этой жизни необходимо платить, и деньгами, и своим временем!
Самое главное в нашей жизни — это время! Его не купить и время не взять нигде, оно есть у каждого и оно ограниченно! Но сэкономить свое время на обучение и ускорить получение результата можно заплатив за этого деньгами. Сегодня это вполне реально и правильно!
![]()
Все ссылки на эти нейросети + огромная масса других сетей доступна в моем бусти-канале вот здесь или достается БОНУСОМ всем покупателям курса Эволюция. Если вы ранее приобрели этот курс и там еще не было этого бонуса — смело пишите мне и укажите номер оплаченного заказа — вышлю этот бонус в ответном сообщении. С сегодняшнего дня этот БОНУС теперь доступен всем кто приобретает курс Эволюция. Он будет приходить на автомате, сразу после приобретения курса вместе с другими бонусами к курсу от меня.
Напомню, что свой Бусти-канал веду и для вас и для себя. Всякий шлак там не публику, а «просеиваю» и даю только реально рабочие схемы заработка + полезную информацию. Вкладываю огромное количество времени на то, чтобы мой Бусти-канал помог каждому смело начать свой заработок в Интернете, присоединяйтесь!
Где научиться специальности?
Как я уже говорила, для профессии дата-сайентист необходимо профильное образование программиста или математическое. А чтобы освоить специфику именно работы с большими массивами данных как структурированных, так и неструктурированных, можно дополнительно пойти на специализированные курсы.
Предлагаю рассмотреть несколько таких вариантов:
1. «Профессия Data Scientist» от SkillBox
SkillBox – онлайн-университет, участник проекта Skolkovo, обладатель премии рунета за 2018 и 2019 годы.
- Чему научитесь: программировать на Python, работать с базами данных, визуализировать результаты, применять нейронные сети для решения реальных задач.
- Длительность обучения: более 1,5 лет.
- Формат обучения: онлайн-лекции, воркшопы, домашние задания, 2 дипломных проекта-соревнования на Kaggle; работа с наставником.
- Преимущества: рассрочка платежа, первый платеж только через 6 месяцев; 2 специальности в одной программе; помощь в трудоустройстве; 1,5 года стажировки в специализированной компании; диплом установленного образца.
- Стоимость: Общая стоимость около 162 000 рублей; возможна рассрочка без переплат по 3 675 рублей в месяц, начиная с 7-го месяца обучения.
![]()
2. «Профессия Data Scientist» от SkillFactory
SkillFactory – специализированная онлайн-школа по обучению Python, Data Science, Machine Learning, разработке и управлению продуктами. На рынке с 2016 года.




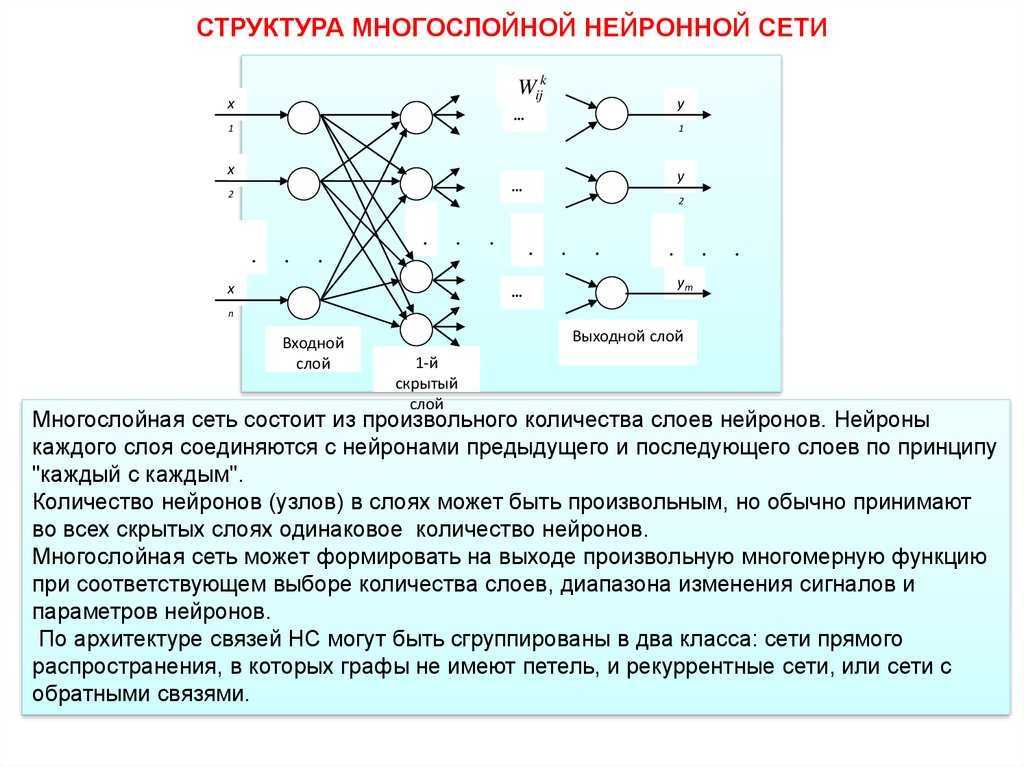

- Чему научитесь: основам программирования на языке Python; изучите математику и статистику для специализации; освоите практическое машинное обучение и нейронные сети; дополнительно изучите менеджмент для управления проектом и командой.
- Длительность обучения: 24 месяца.
- Формат обучения: занятия в форме тренажера, практика с проверкой домашних заданий, работа с куратором, занятия по 6 часов в неделю.
- Преимущества: курсы-тренажеры; реальные проекты для портфолио; помощь персональная от ментора; соревнования и хакатоны; помощь в трудоустройстве; возможность выбрать уровень обучения (junior, middle, senior); сертификат школы; беспроцентная рассрочка платежа.
- Стоимость: около 220 000 рублей за базовый курс, или в рассрочку по 9 722 рублей в месяц.
![]()
3, «Data Scientist» от Нетологии
Нетология – онлайн-университет, который за программу «Профессия Data Scientist» в 2019 году получил премию «Знак качества» в номинации «Подготовка профессионалов цифровой индустрии».
- Чему научитесь: работать с SQL, использовать Python и библиотеки, строить модели машинного обучения.
- Длительность обучения: 12 месяцев.
- Формат обучения: вебинары и онлайн-лекции, практика, домашние задания, лабораторные и проектные работы, сопровождение ментора.
- Преимущества: первый платеж через полгода; диплом о профессиональной переподготовке установленного образца; помощь в трудоустройстве; 10 кейсов в портфолио; пошаговый план погружения в профессию.
- Стоимость: 126 000 рублей, или по 5 250 рублей в месяц на 2 года.
![]()
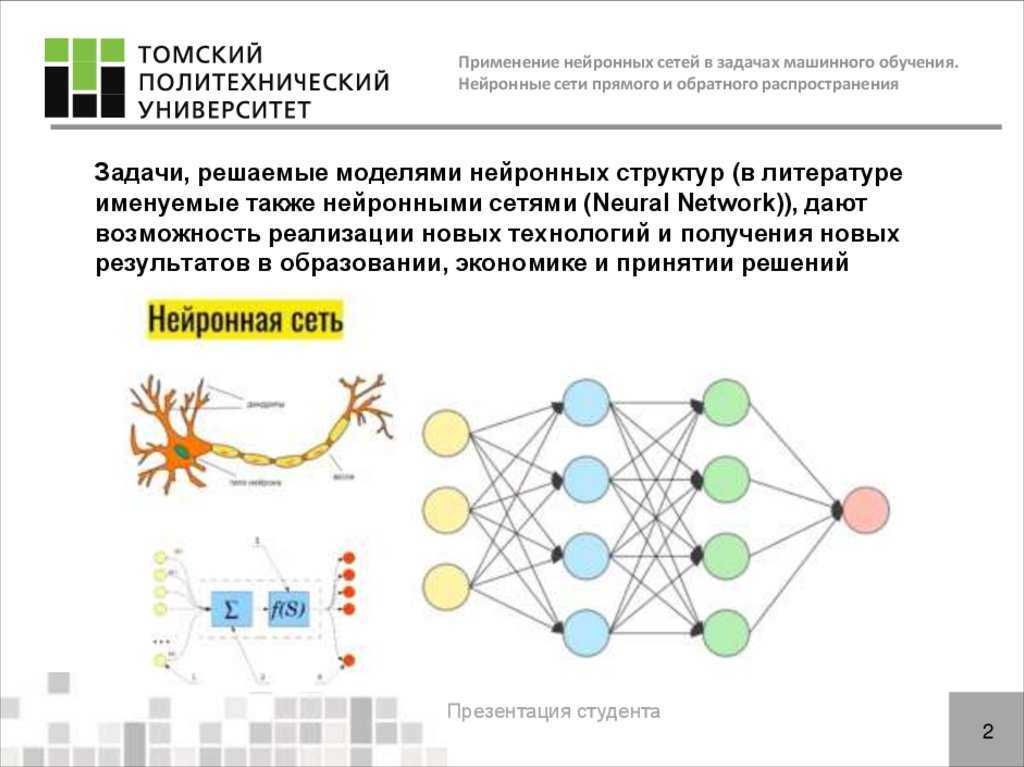
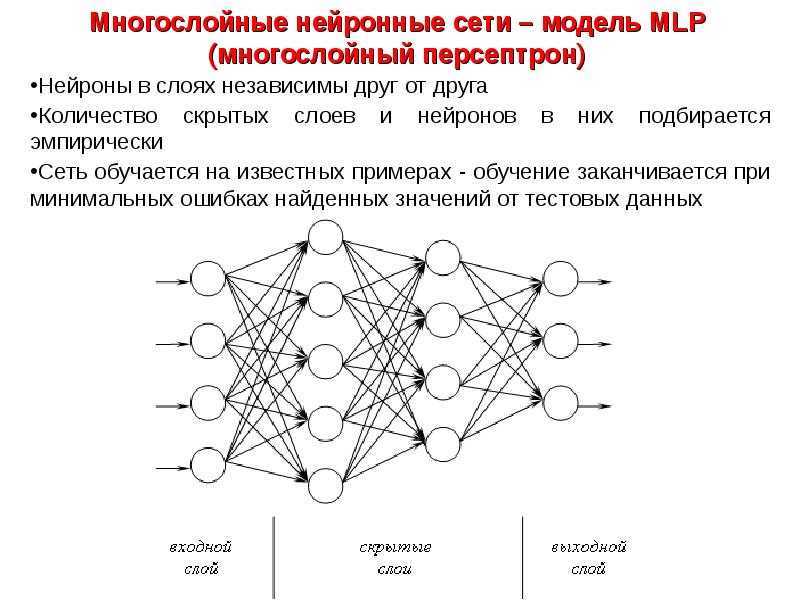
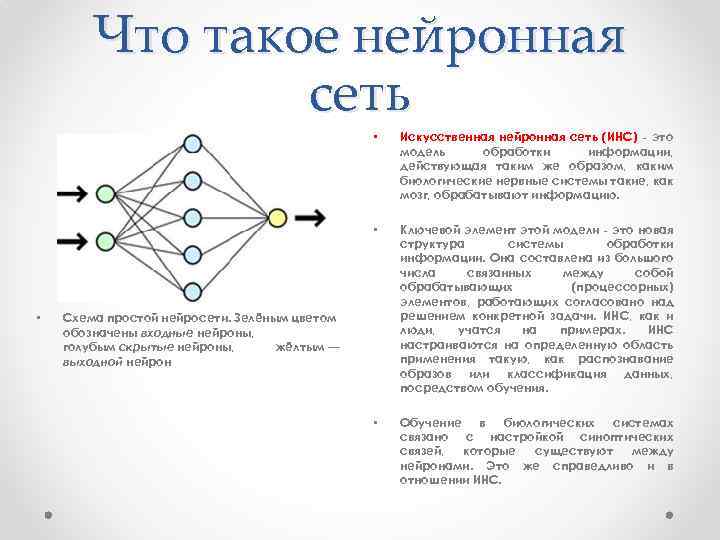
Что такое нейросеть и как работает нейронные сети?
Нейронные сети. Сейчас мы слышим это слово почти повсюду. Дошло до того, что нейронные сети можно встретить даже в холодильниках (это не шутка). Нейронные сети широко используются алгоритмами машинного обучения, которые сегодня можно встретить не только в компьютерах, но и во многих других электронных устройствах, включая смартфоны и бытовую технику.
Мы могли бы обойти это стороной, но задумывались ли вы когда-нибудь, что на самом деле представляют собой эти нейронные сети? Разработка нейронных сетей является ключевой для многих компаний, занимающихся новыми технологиями.
Концепция искусственного нейрона была разработана еще во время Второй мировой войны. Во второй половине двадцатого века многие увлеклись возможностями искусственного интеллекта — преждевременно. Сегодня вычислительные мощности и алгоритмы позволяют машинам выполнять задачи, которые до недавнего времени были подвластны только человеку.
![]()
Что такое нейронные сети? Не волнуйтесь, этот материал не будет академической лекцией. На рынке существует довольно много публикаций, в том числе и на русском языке, которые очень профессионально и достоверно объясняют этот вопрос с научной точки зрения. Основы работы нейронных сетей не изменились, а сама концепция, математическая модель искусственного нейрона, была разработана еще во время Второй мировой войны.
То же самое можно сказать и об Интернете, который сегодня несравненно более развит, чем в то время, когда в мире было отправлено первое электронное письмо. Основы Интернета, фундаментальные протоколы, существовали с момента его создания.
Каждая сложная концепция строится на фундаменте более древних структур. То же самое и с нашим мозгом: самая молодая кора головного мозга не может функционировать без эволюционно самого старого элемента — ствола мозга, который находится в нашей голове с гораздо более древних времен, чем время существования нашего вида на этой планете.
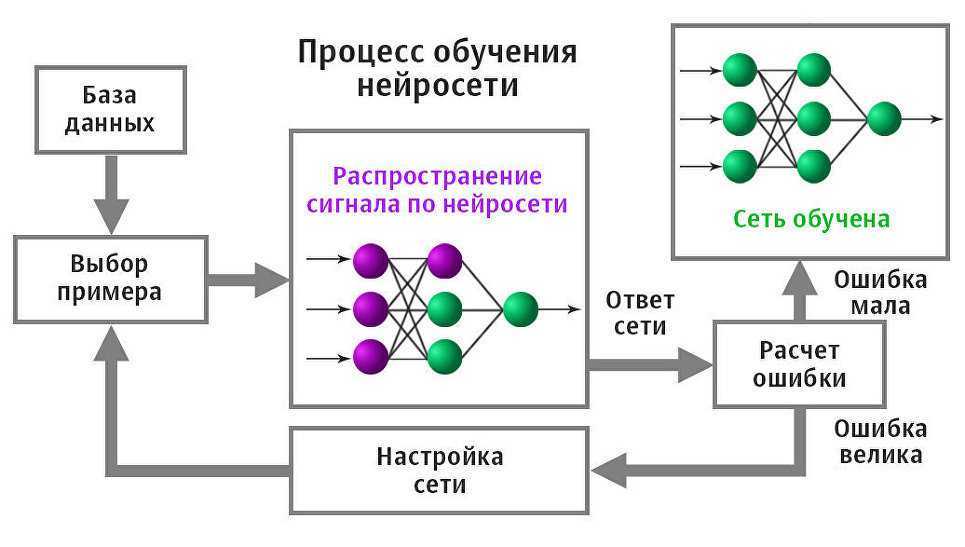
Краткая история нейросетей
Прежде всего, отметим, что нейронные сети – это не единственные методы машинного обучения и искусственного интеллекта. Помимо нейросетей в классе обучения с учителем выделяют методы коррекции и обратного распространения ошибки (backpropagation), а также машину опорных векторов (SVM, Support Vector Machine), применение которой в задаче одноклассовой классификации я описывал в здесь. Еще среди ML-методов различают обучение без учителя (альфа- и гамма-системы подкрепления, метод ближайших соседей), обучение с подкреплением (генетические алгоритмы), частичное, активное, трансиндуктивное, многозадачное и многовариантное обучение, а также бустинг и байесовские алгоритмы .
Тем не менее, сегодня именно нейросети считаются наиболее распространенными ML-инструментами. В частности, они широко используются в задачах распознавания образов, классификации, кластеризации, прогнозирования, оптимизации, принятии управленческих решений, анализе и сжатии данных в различных прикладных областях: от медицины до экономики.
История нейросетей в ИТ начинается с 40-х годов прошлого века, когда американские ученые Маккалок, Питтс и Винер описали это понятие в своих трудах о логическом исчислении идей, нервной активности и кибернетике с целью представления сложных биологических процессов в виде математических моделей.
Здесь стоит упомянуть теоретическую базу нейросетей в виде теоремы Колмогорова-Арнольда о представимости непрерывных функций нескольких переменных суперпозицией непрерывных функций одной переменной. Эта теорема была доказана советскими учеными А.Н. Колмогоровым и В.В. Арнольдом в 1957 году, а в 1987 году переложена американским исследователем Хехт–Нильсеном для нейронных сетей. Она показывает, что любая функция многих переменных достаточно общего вида может быть представлена с помощью двухслойной нейронной сети с прямыми полными связями нейронов входного слоя с нейронами скрытого слоя с заранее известными ограниченными функциями активации (например, сигмоидальными) и нейронами выходного слоя с неизвестными функциями активации.
Из этой теоремы следует, что для любой функции многих переменных существует отображающая ее нейросеть фиксированной размерности, при обучении которой могут использоваться три параметра :
- область значений сигмоидальных функций активации нейронов скрытого слоя;
- наклон сигмоид нейронов этого слоя;
- вид функций активации нейронов выходного слоя.
Еще одной ключевой вехой в истории нейросетей стало изобретение перцентрона Фрэнком Розенблаттом в 60-хх гг. XX века. Благодаря успешным результатам использования перцептронов в ограниченном круге задач (прогнозирование погоды, классификация, распознавание рукописного текста), нейросети стали весьма популярны среди ученых по всему миру. Например, в СССР нейросетями занимались в Институте проблем передачи информации ученые научной школы М. М. Бонгарда и А.П. Петрова (1963-1965 гг.). Однако, поскольку существовавшие на то время вычислительные мощности не могли эффективно реализовать теоретические алгоритмы на практике, исследовательский энтузиазм к этим ML-методам временно упал.
Следующая волна интереса к нейросетям началась спустя 20 лет, в 80-х годах прошлого века и, по сути, продолжается до сих пор. Здесь стоит отметить различные вариации сетей Кохонена и Хопфилда, развившиеся в модели глубокого обучения – тенденции, подробнее о которых мы поговорим далее .
Отличия аналитика данных от data scientist
Аналитик данных ищет возможность улучшить бизнес-показатели. Специалист по data science ищет закономерности в данных и создает практически полезные модели: например, прогнозы погоды.
Аналитик данных проводит анализ, упаковывает результаты в понятный, доступный вид и презентует их. Data scientist может увидеть неявные закономерности в базе данных, упаковать их в понятную и эффективную модель, которая будет работать и приносить измеримый результат.
Аналитик данных изучает то, что уже случилось, и на этой основе делает выводы. Data scientist выявляет закономерности в процессах и прогнозирует, что может случиться и почему.
Аналитик данных собирает данные, обрабатывает их и делает выводы. На основе этих результатов в компании принимают решения, как действовать дальше. Например, какой промокод клиенты используют чаще всего, какой вид контента им нравится. На основе этих данных можно понять, какую площадку для продвижения лучше использовать.
Data scientist тоже собирает и обрабатывает данные, но это только часть его работы. Результатом его деятельности будет модель — код, который написан на основе анализа. Эту модель внедряют в бизнес-процесс, и всё начинает крутиться лучше и эффективнее.
Какую пользу приносит аналитика данных футбольной команде и почему дата-сайентистов держат в секрете
Кирилл Серых:
Анализ данных с каждым годом становится всё более неотъемлемой частью футбола. Так, довольно весомый вклад в победы «Ливерпуля» в 2018-2020 годах сыграли не только тренерское мастерство и новаторство Юргена Клоппа, но и отличная работа Data Science отдела под руководством Иана Грэма. Грэм сумел найти общий язык с тренерским штабом и сыграть большую роль в формировании команды и анализе игры на протяжении последних сезонов.
Классический подход, когда матч воспринимается через призму видения тренера или скаута, зачастую упускает многие вещи, происходящие на поле и является всё же субъективной оценкой. Анализ данных же призван дополнить эту оценку и дать объективные выводы и по каждому игроку, и по командным действиям в целом.
Многие команды не выносят на широкую публику информацию об устройстве своих отделов по Data Science. Например, в бундеслиге Германии играет 18 команд. И мне известны всего 6 из них, в которых есть хотя бы один Data Scientist. В Английской Премьер лиге (АПЛ) и Чемпионшипе (2 главные лиги Англии) такие отделы есть практически у всех. Поэтому то, насколько распространена аналитика в футболе, сильно зависит от страны, футбольного клуба или чемпионата.
Такая секретность связана с тем, что детальный анализ данных даёт возможность получить преимущество команде в том или ином аспекте. Как раз одной из причин успеха «Ливерпуля» была разработка и верное использование математических моделей игры, опережающих на тот момент практически все существующие. Например, они внесли большой вклад в их скаутинг – аналитики «Ливерпуля» подобрали максимально подходящих Клоппу по стилю и принципам игры игроков, что помогло построить одну из лучших команд 2010-ых.
Данные дали «Ливерпулю» конкурентное преимущество несколько лет назад, и чтобы не отставать от лидеров, клубы выделяют все большие бюджеты на data-related сотрудников
Это конкурентное преимущество крайне важно в спорте
Можно провести параллель финала ЧМ-1952, где играли Германия и Венгрия – простой пример с бутсами. Венгры подходили к матчу в статусе фаворита, и несмотря на счёт 2:2 к середине второго тайма, доминировали в матче. Но в это время пошёл дождь, и экипировщик сборной ФРГ Ади Дасслер (один из основателей фирмы Adidas) настоял поменять обувь и надеть бутсы с более длинными шипами. Это позволило им меньше скользить на поле, более эффективно участвовать в единоборствах и в итоге выиграть 3:2, забив в конце матча. После этого обувь со сменными шипами стала стандартом индустрии на следующие десятилетия. Поэтому каждый раз, когда появляется инновация, дающая преимущество, глупо не использовать её в команде.
Обучение с подкреплением
Игра в «Арканоид» — самый простой пример обучения с подкреплением:
![]()
Есть агент — то, на что вы воздействуете, что может менять свое поведение, — в данном случае это горизонтальная «палка» внизу. Есть среда, которая описана разными модулями, — это все, что вокруг «палки». Есть награда: когда сетка роняет шарик, мы говорим, что она теряет свою награду.
Когда нейросеть выбивает очки, мы говорим ей, что это здóрово и она работает хорошо. И тогда сеть начинает изобретать действия, которые приведут ее к победе, максимизируют выгоду. Сначала кидает шарик и просто стоит. Мы говорим: «Плохо». Она: «Ладно, кину, подвинусь на один пиксель». — «Плохо». — «Кину, подвинусь на два, влево, вправо, буду рандомно дергаться». Процесс обучения нейросети — очень долгий и дорогой.

Другой пример обучения с подкреплением — это го. В мае 2014 года люди говорили, что компьютер еще не скоро научится понимать, как играть в го. Но уже в следующем году нейросеть обыграла чемпиона Европы. В марте 2016 года AlphaGo обыграла чемпиона мира высшего дана, а следующая версия выиграла у предыдущей с разгромным счетом 100:0, хотя делала абсолютно непредсказуемые шаги. У нее не было никаких ограничений, кроме игры по правилам:
![]()
Зачем учить компьютер играть в игры за бешеные деньги, вкладываться в киберспорт? Дело в том, что обучение движению и взаимодействию роботов в среде стоит еще дороже. Если ваш алгоритм ошибается и разбивает многомиллионный дрон, это очень обидно. А потренироваться на людях, но в Dota, сам Бог велел.
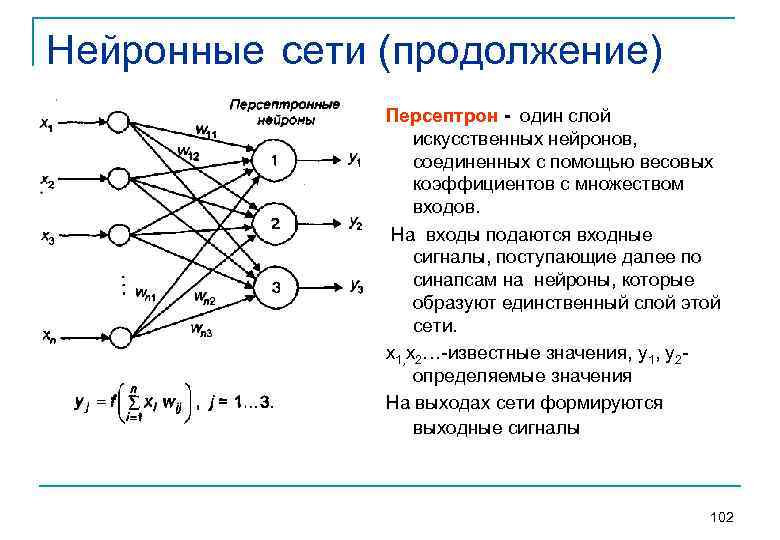
Какие знания нужны дата-сайентисту и где их получить
Линейная алгебра
Без понимания линейной алгебры не обойтись. Например, в линейных моделях участвует скалярное произведение, а нейронные сети описываются на языке операций перемножения векторов и матриц. Также полезно будет понимание собственных чисел и векторов, а SVD-разложение входит в стандартный набор дата-сайентиста.
Книги для базового уровня:
— «Введение в алгебру» А. И. Кострикина — одна из лучших книг по высшей алгебре, включая линейную.
— «Сборник задач по алгебре под редакцией А. И. Кострикина».
— «Задачи по линейной алгебре и геометрии» С. В. Смирнова, А. А. Гайфуллина и А. В. Пенского.
В этом списке два задачника по линейной алгебре с мехмата МГУ. В первом много примеров не только по линейной алгебре, он идеально дополняет учебник Кострикина. Второй позволяет погрузиться в основы линейной алгебры через призму аналитической геометрии.
Теория и задачи для продвинутого уровня:
— Лекции и задачи — «Линейная алгебра и геометрия» А. Л. Городенцева. Лаконичный курс, который автор оттачивал десятилетиями. Он рассчитан на подготовленного в математике читателя.
— «Теоремы и задачи по линейной алгебре» В. В. Прасолова. Книга подойдёт тем, кто уже знаком с линейной алгеброй. В ней есть всё, чтобы освоить дисциплину до «глубины всех глубин». Теория изложена максимально сжато. Большинство примеров взято из математических олимпиад для студентов технических вузов. Ко всем задачам есть решения.
Теория вероятности и статистика
Что стоит изучить: нормальное распределение, многомерное нормальное распределение, центральные предельные теоремы, закон больших чисел и методы оценивания параметров распределений. Это база для любого аналитика, так как одна из его задач — проверять гипотезы с помощью статистических критериев, в которых фигурируют распределения.
Кроме того, в статьях про машинное обучение часто упоминаются вероятностные модели, функции потерь, которые сформулированы на языке максимизации правдоподобия. Поэтому знание математического языка и основных терминов нужно, чтобы понимать, о чём идёт речь.
Книги для базового уровня:
— «Курс теории вероятностей и математической статистики» Б. А. Севастьянова.
— «Теория вероятностей» А. А. Боровкова.
—«Наглядная математическая статистика» М. Б. Лагутина — идеальное введение в статистику.
— «Сборник задач по теории вероятностей» А. М. Зубкова и Б. А. Севастьянова.
Книги для продвинутого уровня:
— «Вероятность» А. Н. Ширяева — отличный учебник, но не для знакомства с теорвером.
— «Задачи по теории вероятностей» — дополнение к учебнику Ширяева.
Математический анализ
Обучение любой модели — это оптимизация, а большинство методов оптимизации основаны на алгоритме градиентного спуска.
Книги для базового уровня:
— «Курс дифференциального и интегрального исчисления» Г. М. Фихтенгольца — классический и максимально подробный учебник. Подходит для первого знакомства с анализом.
— «Сборник задач и упражнений по математическому анализу» Б. П. Демидовича — всемирно известный задачник, выдержавший десятки редакций.
Теория для продвинутого уровня: «Математический анализ» В. А. Зорича — книга для тех, кто обладает некоторым уровнем математической культуры.
Помимо книг можно поискать группу с преподавателем. Желательно, чтобы у него был опыт обучения людей без бэкграунда. Математик научит корректно обращаться с формулами, правильно применять логику, не путать следствие с причиной и переходить от частного к общему.
При этом можно работать с данными без математических знаний: помогут современные библиотеки, в которых есть много готовых решений. Но если специалист столкнётся с новой и нетипичной задачей, могут возникнуть трудности. Например, при детектировании необычных объектов — скажем, летучих мышей. Или при поиске формул новых лекарств. Подобных задач бесконечно много — в них нужно выбирать архитектуры, сравнивать статьи и подбирать данные.
Кто и как собирает данные об игроках и событиях матча
Кирилл Серых:
Сейчас все футбольные данные можно грубо разделить на 2 вида – трекинговые и событийные. Трекинг – это координаты всех игроков на футбольном поле, собранные с частотой от 10 до 50 кадров (строк с координатами) в секунду. Эти данные собираются либо с помощью сертифицированных GPS-датчиков, либо на стадионах ставят специальное оборудование – камеры высокого качества, картинка с которых обрабатывается алгоритмами распознавания объектов, после чего выдаются координаты игроков и мяча.
Во втором случае футбольная лига даёт специальное разрешение на использование этого оборудования во время игры. Например, в Германии обработкой видео и сбором трекинговых данных занимается шведская компания ChyronHego, а дочерняя компания DFL (Немецкая Футбольная Лига, аналог Российской Премьер-Лиги) Sportec Solutions занимается их анализом по играм 1 и 2 Бундеслиги. Также Sportec Solutions собирает событийные данные – информацию о каждом событии, происходящем на поле (пас, удар, перехват мяча, гол). Этим вручную занимается операционный отдел. После этого аналитики оценивают полученные результаты и дают тренеру и игрокам рекомендации для повышения эффективности игры.
Способ сбора данных зависит от конкретного футбольного клуба. В Германии клубы 1 и 2 Бундеслиги получают доступ к данным Sportec Solutions по умолчанию. Кроме того, компания предлагает несколько BI-приложений, позволяющих получать и анализировать информацию как в режиме реального времени, так и до и после матча.
Но информацию по другим лигам, что может быть полезно в том же скаутинге, клубам приходится покупать у сторонних компаний – дата-провайдеров. Помимо доступа к сырым данным эти компании предлагают специальный софт, позволяющий анализировать уже агрегированную статистику и использовать анализ видео. Клубы не всегда раскрывают информацию о том, чьими клиентами они являются.
Некоторые клубы, как тот же «Ливерпуль» пытаются собирать данные самостоятельно: мерсисайдцы купили французский стартап SkillCorner, чей главный продукт – сбор трекинговых данных по бродкастингу. Однако их методика измерения не даёт 100% точности, потому что ТВ-картинка не охватывает большую часть поля и игроков и полученных данных пока что не хватит, чтобы качественно откалибровать модели экстраполяции движения игроков и мяча. Клуб довольно долго не давал информацию о покупке стартапа, хотя в индустрии ходили слухи, что они хотят собрать как можно больше трекинговых данных по разным лигам своими силами.
Также буквально на днях один из провайдеров данных StatsBomb анонсировал релиз StatsBomb360 – более расширенный набор событийных данных, включающий не только координаты игроков, участвующих в событии, но и координаты всех игроков на поле в этот момент. По утверждению компании, этот набор даёт от 85 до 90% информации от полного сета трекинговых данных. На мой взгляд, это достаточно спорное утверждение, требующее детального рассмотрения этих данных. Однако на данный момент это действительно большой шаг внутри индустрии. Неудивительно, что одним из их первых клиентов стал «Ливерпуль».







Качество и объём покупаемых данных зависит от бюджетов клубов на подобные расходы. Их стоимость варьируется в зависимости от чемпионата и качества данных. Например, два года назад я покупал данные у компании WyScout по голландской лиге, и API-доступ к событийным данным стоил 3600 евро в год. А покупка данных у таких компаний как Opta Pro может стоить от 60000 до 80000 евро в год.
В целом по индустрии собирать унифицированные качественные данные пока ещё сложно. Те же события по одному матчу у разных провайдеров могут иметь расхождения в несколько метров и секунд в зависимости от компании. Собрать унифицированные трекинговые данные ещё сложнее, как минимум, с юридической точки зрения. Например, в Германии только ChyronHego имеет доступ к установке своего оборудования, и данные по Бундеслигам доступны только немецким клубам. Если даже на это закрыть глаза, то так как объём трекинговых данных для одного матча (3,6 миллиона строк для частоты 25 кадров в секунду против 1600-1800 событий за матч в среднем), то «шум» или погрешности этих данных гораздо сложнее устранить. И нужно не забывать о том, что трекинг собирается разными методами в разных лигах.
Уровень 1. Самое простое объяснение
![]()
DALL·E 2 состоит из трёх больших частей, базу для которых разработали в Google, но «собрали» в OpenAI.
Первая нейросеть «читает» текст и рисует «черновик» будущего изображения.
Вторая нейросеть превращает «черновик» в маленькое конечное изображение.
Третья нейросеть увеличивает эту маленькую картинку в 16 раз, добавляя необходимые детали.
Готово!
Поэтапно это происходит так:
1. Первая нейросеть называется CLIP, она переводит наш написанный (человеческий) текст в компьютерный язык в виде цифр.
2. Далее CLIP превращает этот набор цифр в таблицу с другими цифрами. Такая таблица играет роль «наброска» или «скелета», по которому создаётся конечное изображение. Чтобы всё сработало, CLIP тренировали на 600 миллионах картинок и подписей к ним.
3. «Черновик» переходит во вторую нейросеть под названием GLIDE.
4. Вторая нейросеть GLIDE берёт первоначальный компьютерный текст из пункта 1 и полученную схему из пункта 2, совмещает данные с них. На основе такого микса она создаёт серый зернистый квадрат, из которого постепенно убирает зерно и тем самым проявляет картинку в плохом качестве. Этот метод проявки называется «применение Диффузной модели».
5. Третья нейросеть увеличивает качество картинки в 16 раз и показывает нам финальный результат.
Но эти этапы озвучены весьма упрощённо: на самом деле в DALL·E 2 работают не сами нейросети, а только их части. Например, изначально CLIP вообще не умела рисовать изображения, её задача была ровно противоположной: описывать текстом то, что она видит.
Рассмотрим эти моменты подробнее.
Как происходит работа с данными на примере проекта «Футбол в цифрах»
Владимир Герингер:
«Футбол в цифрах» – это некоммерческий проект трёх энтузиастов, неравнодушных к футболу и аналитике данных. Мы собираем данные из открытых источников о различных турнирах и формируем по ним единую базу данных.
В российском футболе давно наметился негативный тренд – уже не первый сезон наши команды не могут показать хороших результатов в еврокубках, а сборная с трудом зарабатывает очки в международных соревнованиях. Мы считаем, что все проблемы начинаются ещё на этапе воспитания молодых футболистов. Так у нас родилась идея собирать и анализировать данные по юношеской футбольной лиге (ЮФЛ), чтобы понять, в каком состоянии находится наш юношеский и молодёжный футбол – основные стадии становления будущих профессиональных футболистов.
Проанализировав данные в комплексе, мы хотим понять основные закономерности и реалии подготовки подрастающего поколения, а самое главное – выработать эффективные решения для развития и улучшения игры российских команд.